线性模型的基本形式
假设样本空间中的所有样本均服从某一分布,从样本空间中独立同分布的进行采样所得的样本集作为训练集。
线性模型指的是假设可以通过属性空间中的各个属性的线性组合所得到的预测函数对新样本进行预测,即对给定的新样本作为输入,用使用预测函数所得到的输出值作为新样本的真实值的预测。
设xx={x1;x2;⋯;xd} 为具有d个属性的样本(也称实例),其中xi 代表的是样本xx 的第i个属性的取值。需要注意的是,xi 是一个样本所给定的标量值,它不是变量,且它是已知量而不是未知量。WW={w1;w2;⋯;wd} 为权重列向量,其中wi 代表的是样本xx 的第i个属性的权重。根据上述假设和定义,可以得到线性模型的一般形式:
f(xx)=w1x1+w2x2+⋯+wdxd+b=wwTxx+b
其中b 为偏置项,是一个标量。
NOTICE
-
线性模型指的是可以通过样本属性的线性组合作为预测函数对新样本的实际值进行预测。由于这个预测函数是线性的,故称该模型(映射关系)为线性模型。
-
上述线性模型中的未知量为ww,b ,已知量为xx
线性回归
线性模型矩阵化和向量化
使用模型对实值进行预测,称该任务为回归任务;使用线性模型对实值进行预测,称为线性回归。
设数据集D={(xx1,y1),(xx2,y2),⋯,(xxm,ym)} 为从样本空间中独立同分布采样所得到的集合。其中xxi=(xi1;xi2;⋯;xid) 是由d个属性所描述的样本,xid是第i个样本第d个属性的具体取值。
为了能够使用矩阵和向量的形式表示线性模型,将未知量(称为参数)吸收进一个列向量中ww^=(ww;b) ,其维度为d+1 ;对数据集D进行改造,设XX=(xx,I),其中I是维度为d,值为全1的向量。则矩阵X 的维数m×(d+1),则有:
yy^=f(X)=Xww^
结果为一个向量值函数,即:yy^是一个维度为m的列向量。
求解参数ww^
线性回归模型的目标是:从给定数据集中学习得到一个线性模型,以使得实值输出与实际值的误差在某种度量下尽可能的小的那组参量(未知量)ww^。线性回归中常用的误差度量为均方误差MSE。
设向量yy 为训练集的样本的实际值向量,维度为m。采用MSE作为度量标准后,可以将上述学习目标使用数学语言进行描述:
ww^∗=ww^argmin(y−Xww^)T(y−Xww^)
由于目标函数是高维度的凸函数,可以使用求导的方式获得其解析解。设:E=(y−Xww^)T(y−Xww^),对其展开有:
E=(y−Xww^)T(y−Xww^)=yTy−yTXww^−ww^TXTy+ww^TXTXww^
对参数ww^求偏导,有:
∂ww^∂E=∂ww^∂E(yTy−yTXww^−ww^TXTy+ww^TXTXww^)=0−XTy−XTy+(XTX+XTX)ww^=2XT(Xww^−y)
令∂ww^∂E=0,有:
2XT(Xww^−y)=0→XTXww^=XTy
若矩阵XTX 可逆,(即满秩),则可以得到关于参数ww^的解析解:ww^=(XTX)−1XTy ,其中X,y均为已知量。
如果矩阵XTX不可逆,则常用的方法为对采用MSE度量加上一个正则化项,在避免模型过于复杂的同时还可以使得最有求解参数ww^时的矩阵为可逆矩阵。
而对于上述解析解的求解,可以使用数值分析里面的方法进行求解。
对数几率回归
对数几率回归的本质
对数几率回归,也叫逻辑斯蒂回归,它的目的是对离散值的预测,它是一个二分类的学习器。所谓的对数几率回归只是将线性回归的实值输出再做一次映射,从实值空间到分类空间的映射。
阶跃函数sgn(x)可以将实值压缩为0,1离散值。即:
sgn(x)=⎩⎪⎪⎨⎪⎪⎧10.50x>0.5x=0.5x<0.6
但是阶跃函数是一个不光滑的分段函数,其函数性质较差,因此需要选择一个光滑的函数来阶跃函数进行替代,sigmoid 函数就应运而生:
y=1+e−x1
其图像为:
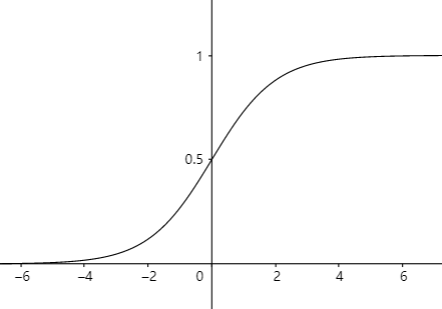
可以看出sigmoid函数可以将实值空间映射到(压缩到)(0,1)区间上。该函数光滑,且只有在正无穷或负无穷处取得1或者0值。
使用sigmoid函数作为线性回归实值输出到分类空间的非线性映射,有:
y=1+e−(wwTxx+b)1
整理上式,有:
ln1−yy=wwTxx+b
由于sigmoid函数满足概率的公理化定义,可以将y理解为正例所出现的概率(即:标签为+1对应的样本为正例,0对应的样本为反例) ,则1−y可以理解为反例所出现的概率。则1−yy描述的是正例所出现的相对概率,称为几率;而ln1−yy描述的是正例所出现的对数几率。这也就是为啥该模型称为对数几率回归。
对数几率模型的数学描述
根据上一节,可以得知y为正例所出现的概率,1−y为反例所出现的概率,即:
y=p(y=1∣xx;ww,b)=p1(xx;ww,b)1−y=p(y=0∣xx;ww,b)=p0(xx;ww,b)
带入ln1−yy=wwTxx+b ,有:
ln1−p1(xx;ww,b)p1(xx;ww,b)=wwTxx+b⇒p1(xx;ww,b)=1+ewwTxx+bewwTxx+b⇒p0(xx;ww,b)=1+ewwTxx+b1
求解参数ww,b
令β=(ww;b), z=(x;1),则上述公式可以改写为:
ln1−p1(xx;ww,b)p1(xx;ww,b)=βTz⇒p1(xx;ww,b)=1+eβTzeβTz⇒p0(xx;ww,b)=1+eβTz1
其中未知量为β 。学习目标为:使得预测的分类的概率尽可能为正确分类值。使用极大似然估计来估计最优参量。
构造对数似然函数:
L(β)=i=1∑mlnp(yi∣zi;β)
而p(yi∣zi;β)可以由
p(yi∣zi;β)=yip1(xx;ww,b)+(1−yi)p0(xx;ww,b)
所表示。原因是由于是2二分类问题,真实值只可能是0或者1,带入上式后可以将分段函数合并成一个函数表达式。将该函数表达式代入对数似然函数有:
L(β)=i=1∑m(ln(yieβTzi+1−yi)−ln(1+eβTzi))
由于yi的可能取值只有0和1,则ln(yieβTzi+1−yi)−ln(1+eβTzi)可以拆为分段函数:
{−ln(1+eβTzi)βTzi−ln(1+eβTzi)yi=0yi=1
上述分段公式又可以根据技巧何为一个函数表达式:
yi(βTzi−ln(1+eβTzi))−(1−yi)ln(1+eβTzi)
则对数似然函数可以写为:
L(β)=i=1∑m(−yiβTzi+ln(1+eβTzi))
上述对数似然函数是凹函数,对对数似然函数取反,则最大化似然函数变为最小化似然函数,即:
β∗=ββargmaxL(β)=ββargmin−L(β)
可以使用数值分析中的方法进行求解。
